Advanced python CoP¶
Table of contents:¶
- TDD
- Doctest
- Live coding
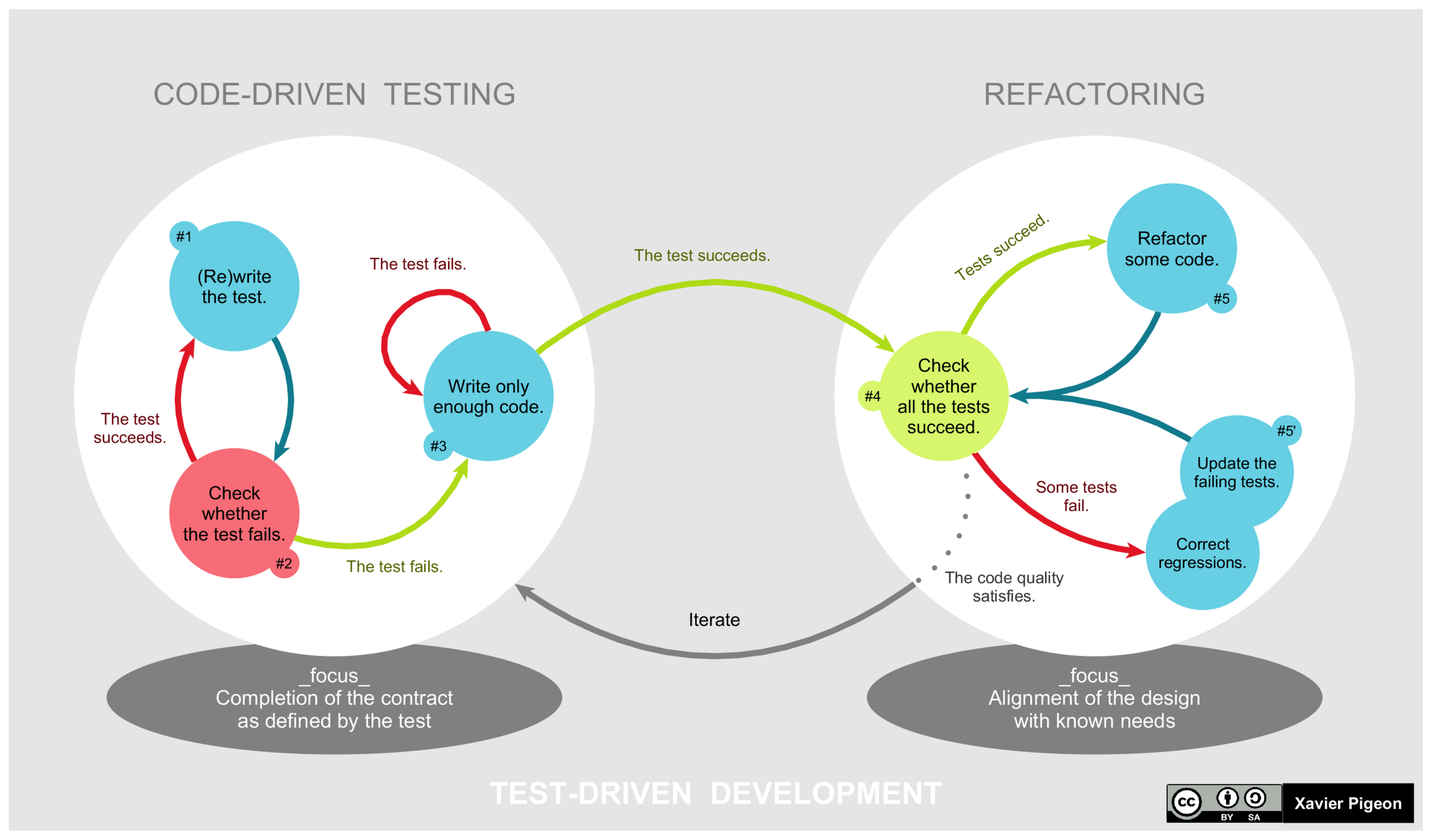
All you need to know about TDD in one picture:¶
In [3]:
%%HTML
<img src=https://upload.wikimedia.org/wikipedia/commons/thumb/0/0b/TDD_Global_Lifecycle.png/2560px-TDD_Global_Lifecycle.png>
</img>
Doctest - write simple unit tests in doc strings¶
In [14]:
def divide(a, b):
"""
>>> divide(4,2)
2.0
>>> divide(2/0)
Traceback (most recent call last):
...
ZeroDivisionError: division by zero
>>> a = 10
>>> b = 5
>>> divide(a,b)
2.0
"""
return a / b
Aaand that's all you need to know about writing doctests.
During development it's best to use IDE runner, but you can programatically run doctests from current file
In [6]:
import doctest
doctest.testmod(verbose=True)
Out[6]:
In automated tests you may use doctest discovery from pytest to find and run all doctests in module recursively
In [ ]:
! pip install pytest --user
In [ ]:
! pytest --doctest-modules
Live coding¶
In [17]:
import io
import re
from typing import Dict, Union
filename = "file.vbf"
def _remove_commented_lines(header_body: str) -> str:
"""
>>> header = "before\\n // comment\\nafter"
>>> _remove_commented_lines(header)
'before\\n after'
"""
return re.sub(r"//[^\n]+\n", "", header_body)
def _read_until(fp: io.BytesIO, pattern: str) -> None:
"""
>>> file = io.BytesIO("trash header {real_body".encode())
>>> _read_until(file, r"header\s*{")
>>> file.read().decode()
'real_body'
"""
value = ""
while not re.search(pattern, value):
value += fp.read(1).decode()
def extract_header_body(fp: io.BytesIO) -> str:
"""
>>> extract_header_body(io.BytesIO("trash \\n header { body} other trash".encode()))
"body"
"""
_read_until(fp, r"header\s*{")
# TODO: not finished
return fp.read().decode()
def parse_vbf_header(header_body: str) -> Dict[str, Union[str, int]]:
pass
with open(filename, "rb") as file:
header_body = extract_header_body(file)
header = parse_vbf_header(header_body)